Optimizing the Netflix API
01 May 2013Originally written for and posted on the Netflix Tech Blog:
About a year ago the Netflix API team began redesigning the API to improve performance and enable UI engineering teams within Netflix to optimize client applications for specific devices. Philosophies of the redesign were introduced in a previous post about embracing the differences between the different clients and devices.
This post is part one of a series on the architecture of our redesigned API.
Goals
We had multiple goals in creating this system, as follows:
### Reduce Chattiness
One of the key drivers in pursuing the redesign in the first place was to reduce the chatty nature of our client/server communication, which could be hindering the overall performance of our device implementations.
Due to the generic and granular nature of the original REST-based Netflix API, each call returns only a portion of functionality for a given user experience, requiring client applications to make multiple calls that need to be assembled in order to render a single user experience. This interaction model is illustrated in the following diagram:
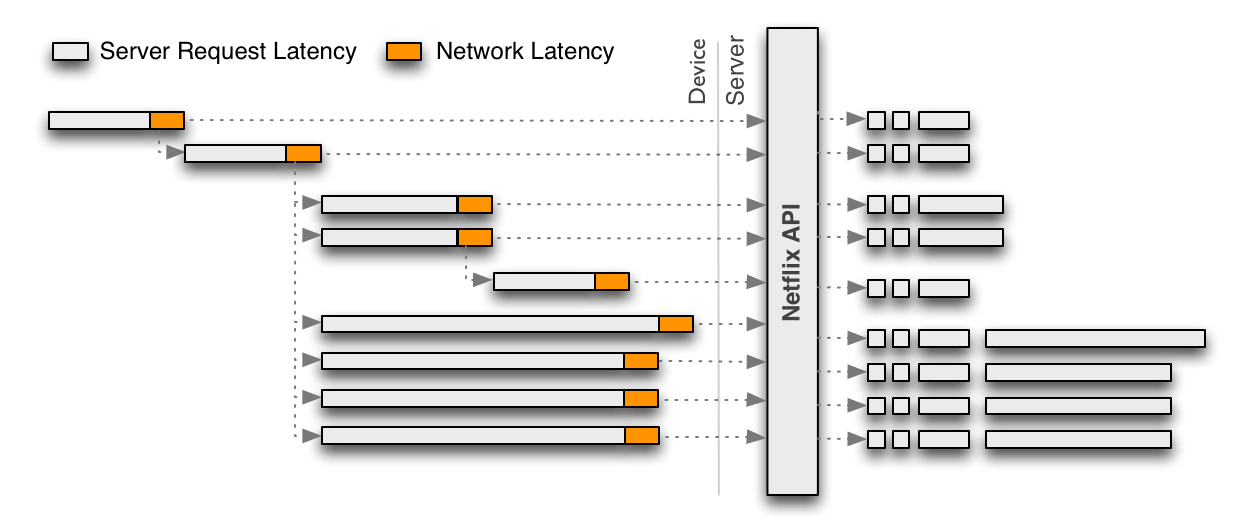
To reduce the chattiness inherent in the REST API, the discrete requests in the diagram above should be collapsed into a single request optimized for a given client. The benefit is that the device then pays the price of WAN latency once and leverages the low latency and more powerful hardware server-side. As a side effect, this also eliminates redundancies that occur for every incoming request.
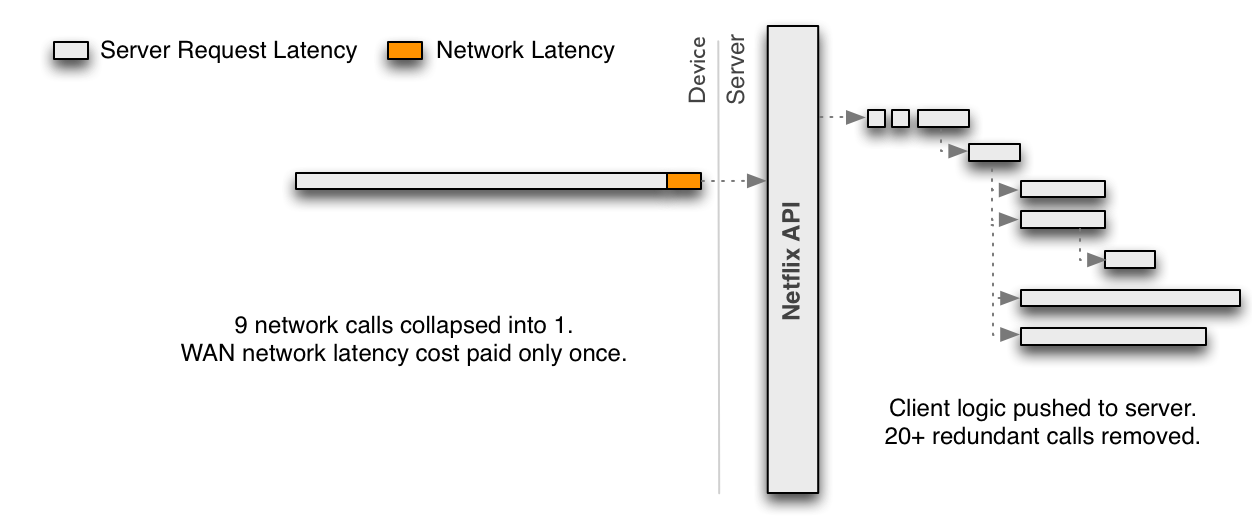
A single optimized request such as this must embrace server-side parallelism to at least the same level as previously achieved through multiple network requests from the client. Because the server-side parallelized requests are running in the same network, each one should be more performant than if it was executed from the device. This must be achieved without each engineer implementing an endpoint needing to become an expert in low-level threading, synchronization, thread-safety, concurrent data structures, non-blocking IO and other such concerns.
### Distribute API Development
A single team should not become a bottleneck nor need to have expertise on every client application to create optimized endpoints. Rapid innovation through fast, decoupled development cycles across a wide variety of device types and distributed ownership and expertise across teams should be enabled. Each client application team should be capable of implementing and operating their own endpoints and the corresponding requests/responses.
### Mitigate Deployment Risks
The Netflix API is a Java application running on hundreds of servers processing 2+ billion incoming requests a day for millions of customers around the world. The system must mitigate risks inherent in enabling rapid and frequent deployment by multiple teams with minimal coordination.
### Support Multiple Languages
Engineers implementing endpoints come from a wide variety of backgrounds with expertise including Javascript, Objective-C, Java, C, C#, Ruby, Python and others. The system should be able to support multiple languages at the same time.
### Distribute Operations
Each client team will now manage the deployment lifecycle of their own web service endpoints. Operational tools for monitoring, debugging, testing, canarying and rolling out code must be exposed to a distributed set of teams so teams can operate independently.
Architecture
To achieve the goals above our architecture distilled into a few key points:
-
dynamic polyglot runtime
-
fully asynchronous service layer
-
functional reactive programming model
The following diagram and subsequent annotations explain the architecture:
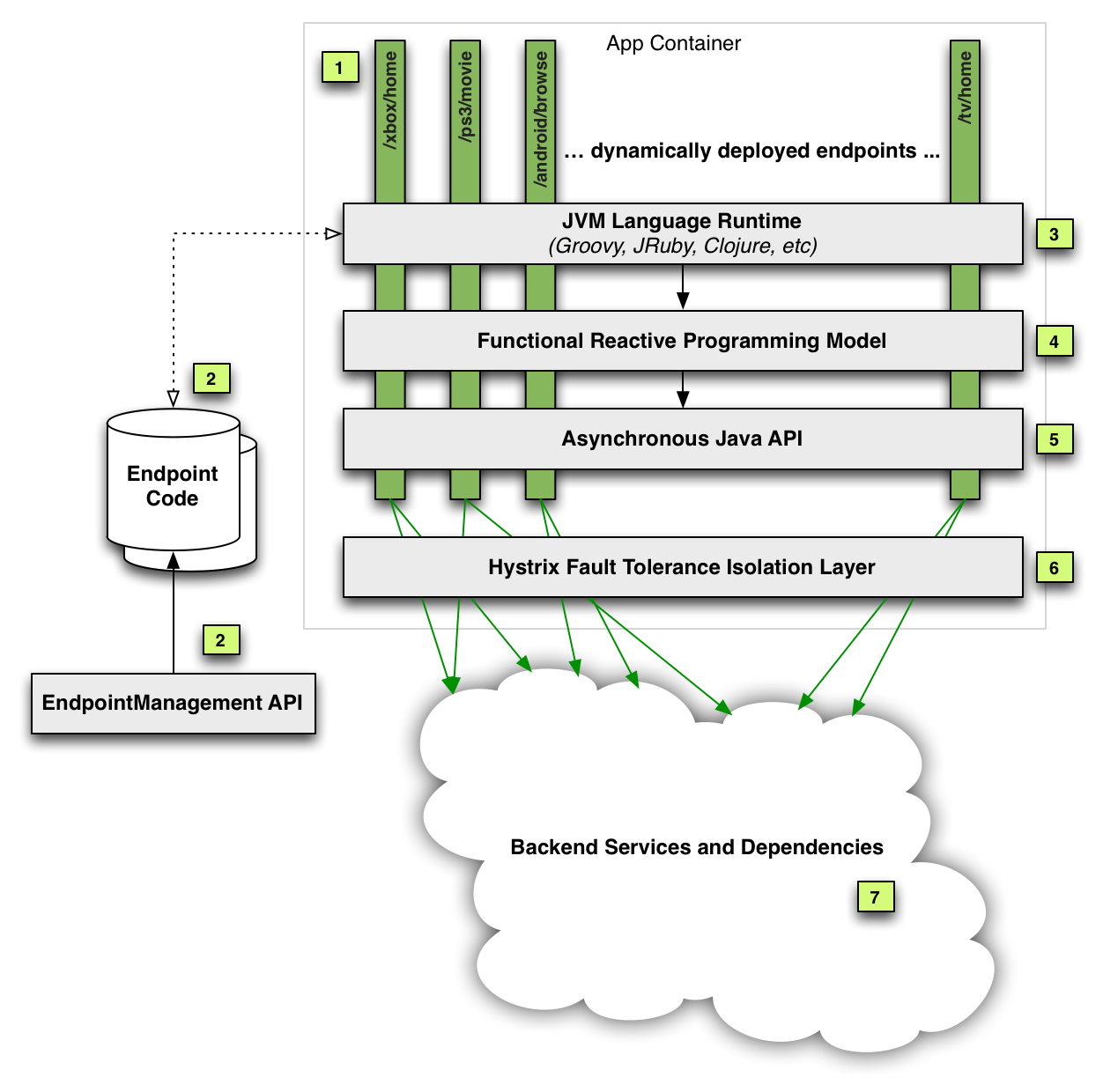
### [1] Dynamic Endpoints
All new web service endpoints are now dynamically defined at runtime. New endpoints can be developed, tested, canaried and deployed by each client team without coordination (unless they depend on new functionality from the underlying API Service Layer shown at item 5 in which case they would need to wait until after those changes are deployed before pushing their endpoint).
### [2] Endpoint Code Repository and Management
Endpoint code is published to a Cassandra multi-region cluster (globally replicated) via a RESTful Endpoint Management API used by client teams to manage their endpoints.
### [3] Dynamic Polyglot JVM Language Runtime
Any JVM language can be supported so each team can use the language best suited to them.
The Groovy JVM language was chosen as our first supported language. The existence of first-class functions (closures), list/dictionary syntax, performance and debuggability were all aspects of our decision. Moreover, Groovy provides syntax comfortable to a wide range of developers, which helps to reduce the learning curve for the first language on the platform.
### [4 & 5] Asynchronous Java API + Functional Reactive Programming Model
Embracing concurrency was a key requirement to achieve performance gains but abstracting away thread-safety and parallel execution implementation details from the client developers was equally important in reducing complexity and speeding up their rate of innovation. Making the Java API fully asynchronous was the first step as it allows the underlying method implementations to control whether something is executed concurrently or not without the client code changing. We chose a functional reactive approach to handling composition and conditional flows of asynchronous callbacks. Our implementation is modeled after Rx Observables.
### [6] Hystrix Fault Tolerance
As we have described in a previous post, all service calls to backend systems are made via the Hystrix fault tolerance layer (which was recently open sourced, along with its dashboard) that isolates the dynamic endpoints and the API Service Layer from the inevitable failures that occur while executing billions of network calls each day from the API to backend systems.
The Hystrix layer is inherently mutlti-threaded due to its use of threads for isolating dependencies and thus is leveraged for concurrent execution of blocking calls to backend systems. These asynchronous requests are then composed together via the functional reactive framework.
### [7] Backend Services and Dependencies
The API Service Layer abstracts away all backend services and dependencies behind facades. As a result, endpoint code accesses “functionality” rather than a “system”. This allows us to change underlying implementations and architecture with no or limited impact on the code that depends on the API. For example, if a backend system is split into 2 different services, or 3 are combined into one, or a remote network call is optimized into an in-memory cache, none of these changes should affect endpoint code and thus the API Service Layer ensures that object models and other such tight-couplings are abstracted and not allowed to “leak” into the endpoint code.
## Summary
The new Netflix API architecture is a significant departure from our previous generic RESTful API.
Dynamic JVM languages combined with an asynchronous Java API and the functional reactive programming model have proven to be a powerful combination to enable safe and efficient development of highly concurrent code.
The end result is a fault-tolerant, performant platform that puts control in the hands of those who know their target applications the best.
Following posts will provide further implementation and operational details about this new architecture.