Application Resilience in a Service-Oriented Architecture using Hystrix
10 Jun 2013Originally written for programming.oreilly.com:
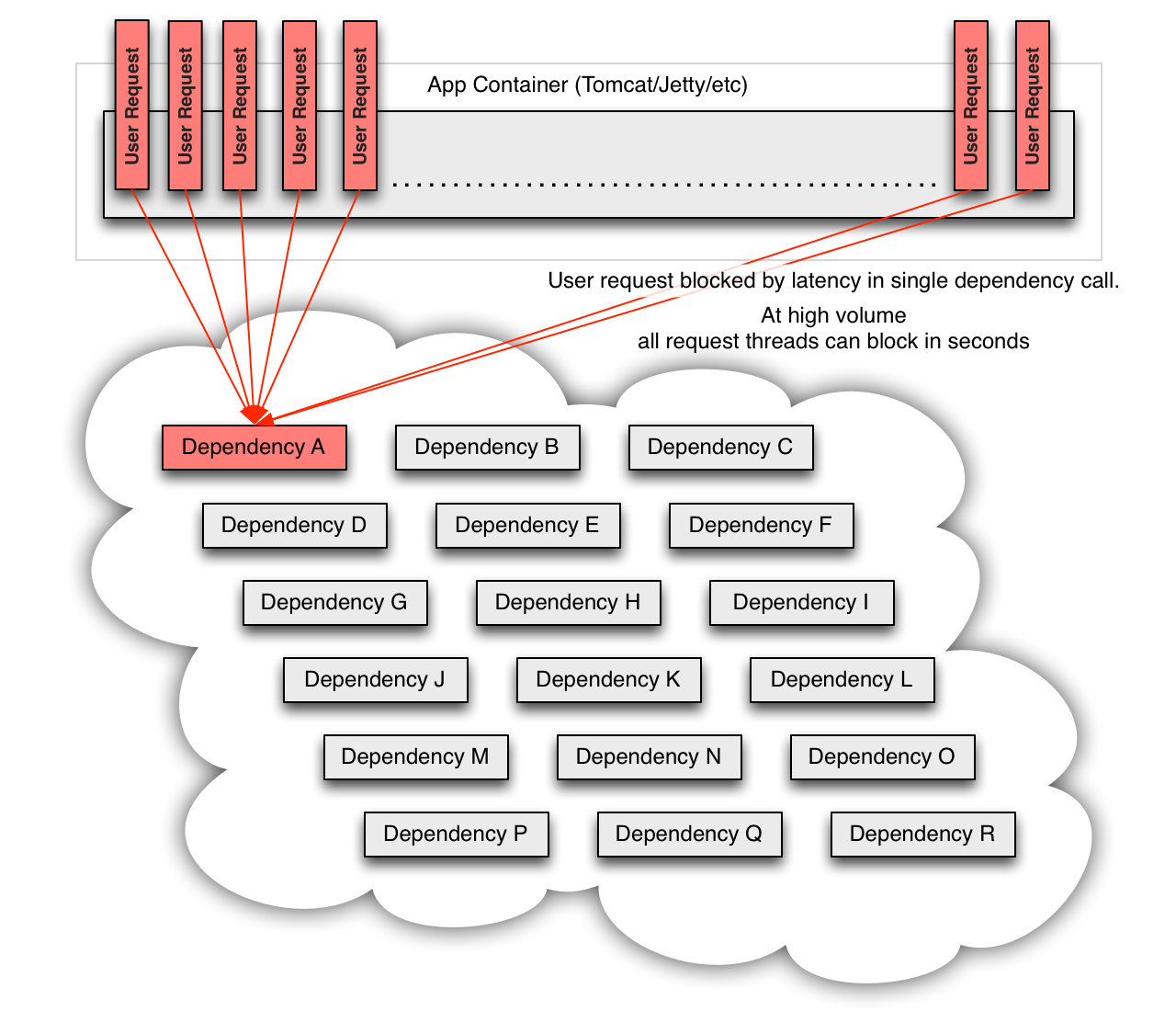
Web-scale applications such as Netflix serve millions of customers using thousands of servers across multiple data centers. Unmitigated system failures impact user experience, product image, company brand and potentially even revenue. Service-oriented architectures such as these are too complex to completely understand or control and must be treated accordingly. The relationships between nodes are constantly changing as actors within the system independently evolve. Failure in the form of errors and latency will emerge from these relationships and resilient systems can easily “drift” into states of vulnerability. Infrastructure alone cannot be relied upon to achieve resilience. Application instances, as components of a complex system, must isolate failure and constantly audit for change.
At Netflix, we have spent a lot of time and energy engineering resilience into our systems. Among the tools we have built is Hystrix which specifically focuses on failure isolation and graceful degradation. It evolved from a series of production incidents involving saturated connection and/or thread pools, cascading failures, and misconfigurations of pools, queues, timeouts and other such “minor mistakes” which led to major user impact.
This open source library follows these principles in protecting our systems when novel failures inevitably occur:
-
Isolate client network interaction using the bulkhead and circuit breaker patterns.
-
Fallback and degrade gracefully when possible.
-
Fail fast when fallbacks aren’t available and rapidly recover.
-
Monitor, alert and push configuration changes with low latency (seconds).
Restricting concurrent access to a given backend service has proven to be an effective form of bulkheading as it limits the resource utilization to a concurrent request limit smaller than the total resources available in an application instance. We do this using two techniques, thread pools and semaphores. Both provide the essential quality of restricting concurrent access while threads provide the added benefit of timeouts so the caller can “walk away” if the underlying work is latent.
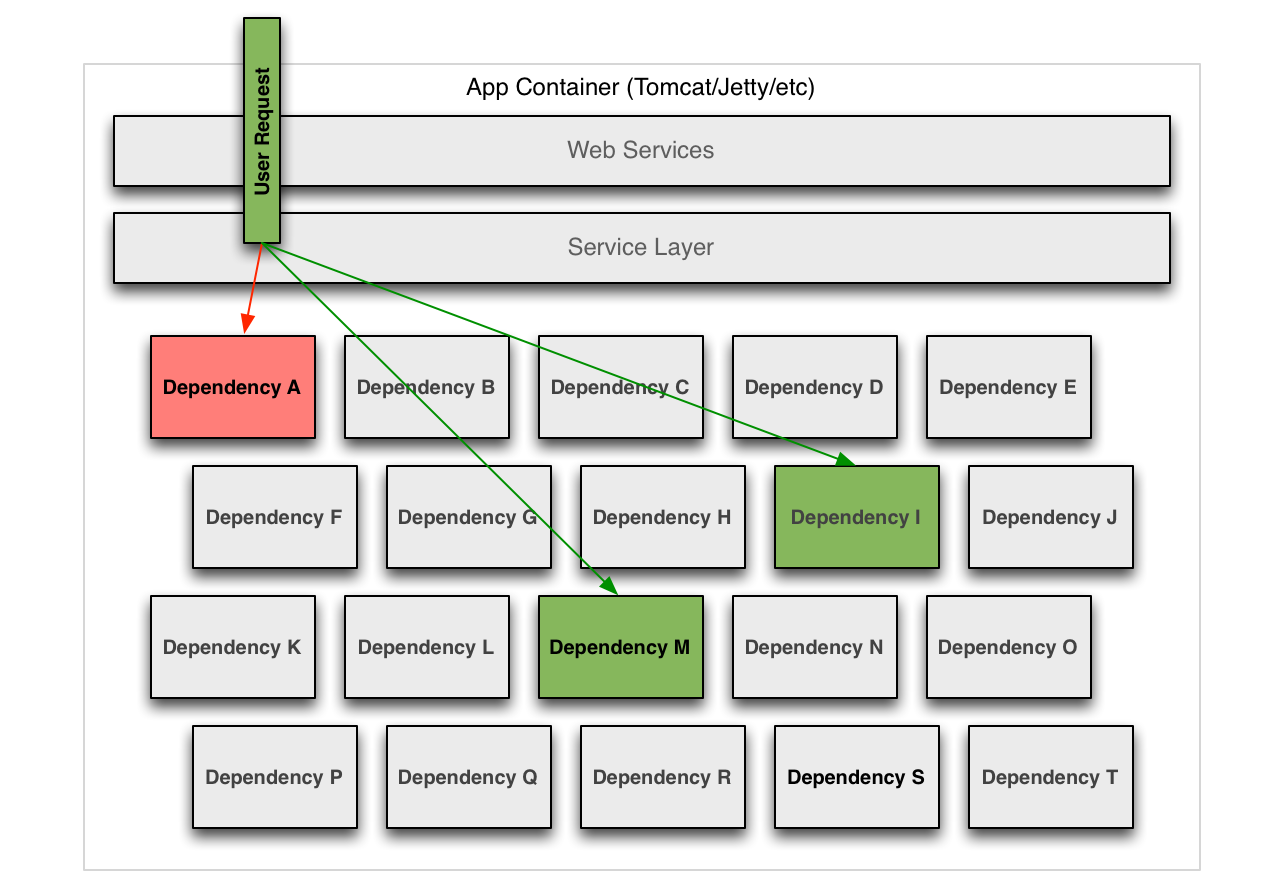
Isolating functionality rather than the transport layer is valuable as it not only extends the bulkhead beyond network failures and latency, but also those caused by client code. Examples include request validation logic, conditional routing to different or multiple backends, request serialization, response deserialization, response validation, and decoration. Network responses can be latent, corrupted or incompatibly changed at any time which in turn can result in unexpected failures in this application logic.
Mixed environments will also have several types of clients for the many different types of backends. Each has different configurations and most clients don’t expose themselves easily for auditing or modification in a production environment. Unfortunately it is also generally true that default configurations are not optimal and despite best efforts these leak into a system (particularly via transitive dependencies) and it only takes one misconfigured client to expose a vulnerability that results in a system outage.
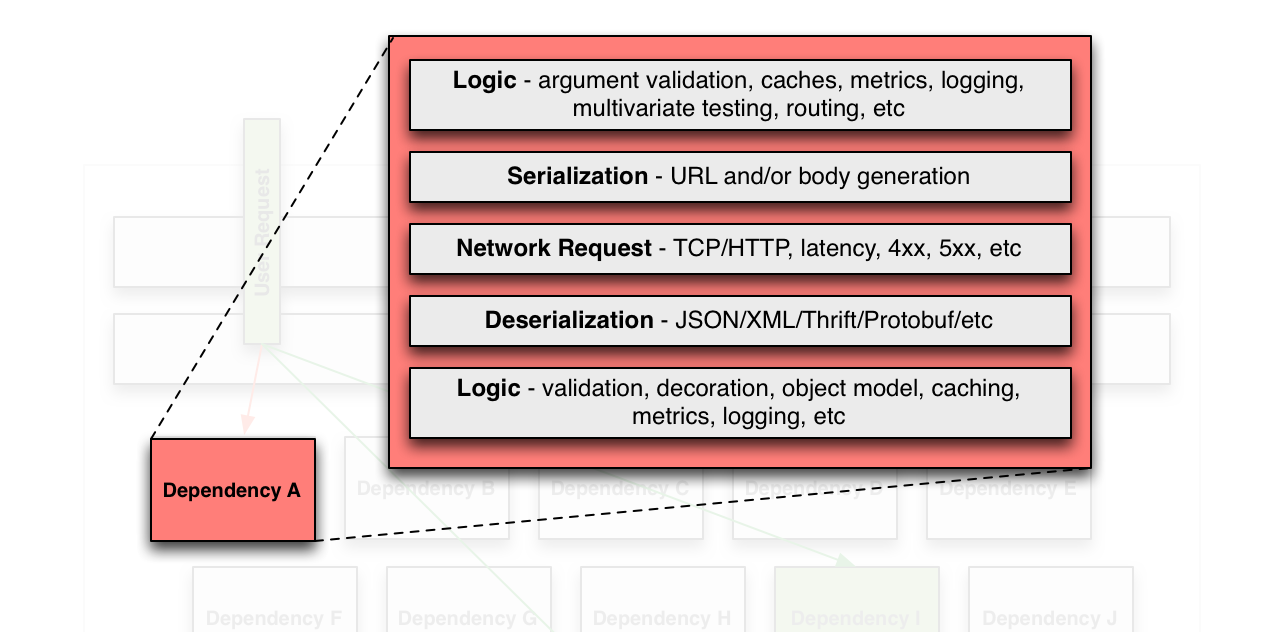
Bulkheading around all of this - transport layer, network clients and client code - permits reliable protection against changing behavior, misconfigurations, transitive dependencies performing unexpected network activity, response handling failures and overall latency regardless of where it comes from.
Applying bulkheads at the functional level also enables addition of business logic for fallback behavior to allow graceful degradation when failure occurs. Failure may come via network or client code exceptions, timeouts, short-circuiting, or concurrent request throttling. All of them, however, can now be handled with the same “failure handler” to provide fallback responses. Some functionality may not be able to gracefully degrade so will “fail fast” and shed load until recovery, but many others can return stale data, use secondary systems, use defaults or other such patterns.
Operations and insight into what is going on is equally important to the actual isolation techniques. The key aspects of this are low latency metrics, low latency configuration changes and common insight into all service relationships regardless of how the network transport is being implemented.
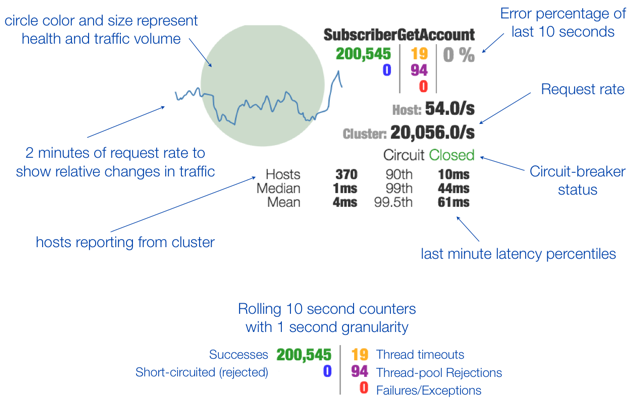
A low-latency (~1 second) metrics stream is exposed to aggregate metrics from all application instances in a cluster. We use this stream for alerting and dashboards (as shown in a video clip below and the annotated image above) to provide visualizations of traffic, performance and health of all bulkheads on a system. Near real-time metrics have improved mean-time-to-detection (MTTD) and mean-time-to-recovery (MTTR) and increased operational effectiveness when doing deployments or dealing with production incidents. Configuration changes visually roll across a cluster of servers in seconds and the impact is seen immediately.
[youtube http://www.youtube.com/watch?v=zWM7oAbVL4g&w=640&h=360]
Auditing production is essential to maintaining a resilient system. Latency Monkey is used in production to inject latency into the system relationships of the service-oriented architecture. Latency can be far more damaging to a distributed system and is more difficult to address than “fast fail” of machines or code. While running latency simulations Hystrix real-time monitoring allows us to rapidly see the impact, determine if we are safe or need to end the test. Most times these simulations “light up” a Hystrix bulkhead on our dashboards to show they are doing their job to isolate the latency but sometimes we reveal a regression and quickly discover it, end the test and pursue a resolution which is validated in the next test run.
Another form of auditing being applied is tracking all network traffic leaving the JVM and finding those not isolated behind a bulkhead. We use this like a “canary in a coalmine” that permanently runs and takes a small percentage of production traffic to find network traffic that springs up without isolation. This can occur in the initial canary deployment with new code, or it may occur when unexpected code paths are enabled via transitive dependencies when AB tests are turned on or production configuration is changed and pushed out to a fleet of existing servers.
Graceful degradation is not purely a server-side consideration and our device and UI teams play an equally important role in making the user experience robust and capable of degrading gracefully. For example, the server can use bulkheading to isolate failure and choose to “fail silently” on a portion of a request considered optional but UIs must behave correctly or we may cause the client to fail as it tries to render data not present in a response. Fault injection via Hystrix execution hooks enables device teams to target specific UIs, devices and accounts to test failure, latency and fallback scenarios and determine whether the client code responds as it should.
Engineering resilience into an application is critical to achieving fault and latency tolerance. Operational considerations and support by client applications are equally important. These principles can be applied in many different ways and approaches will differ by language, technology stack and personal preference but hopefully our experiences, and perhaps even our open source software, can inspire improved resilience in your systems.
![]()